I’ve already decided what I’ll buy first when I win the lottery and it’s going to be the Remarkable Paper Pro.
I saw a C-level executive from a client using this device in a meeting and I was immediately impressed by its design. The form factor, the way it writes like paper and the feature where you can just write on-top of a PDF files is just so cool.
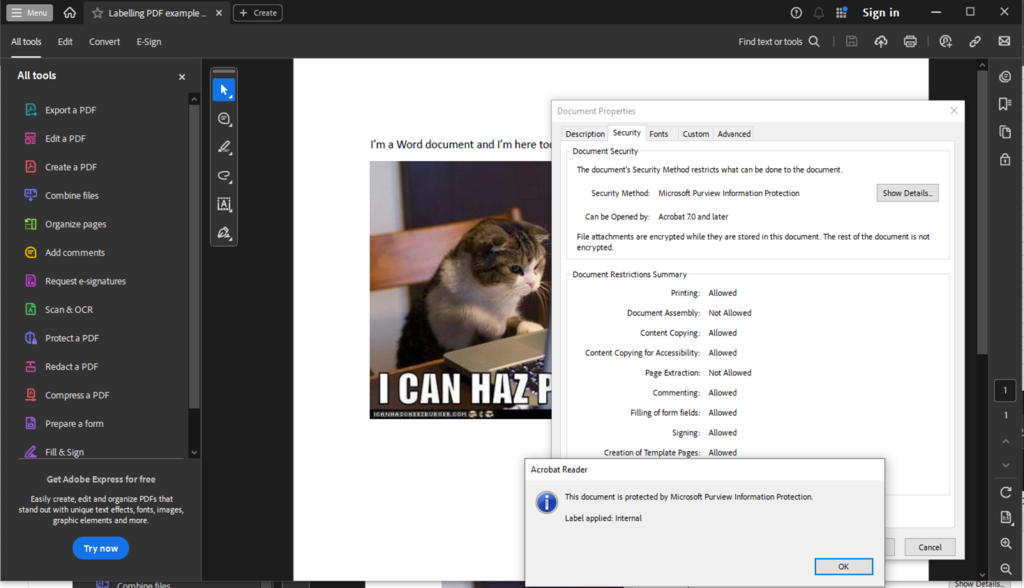
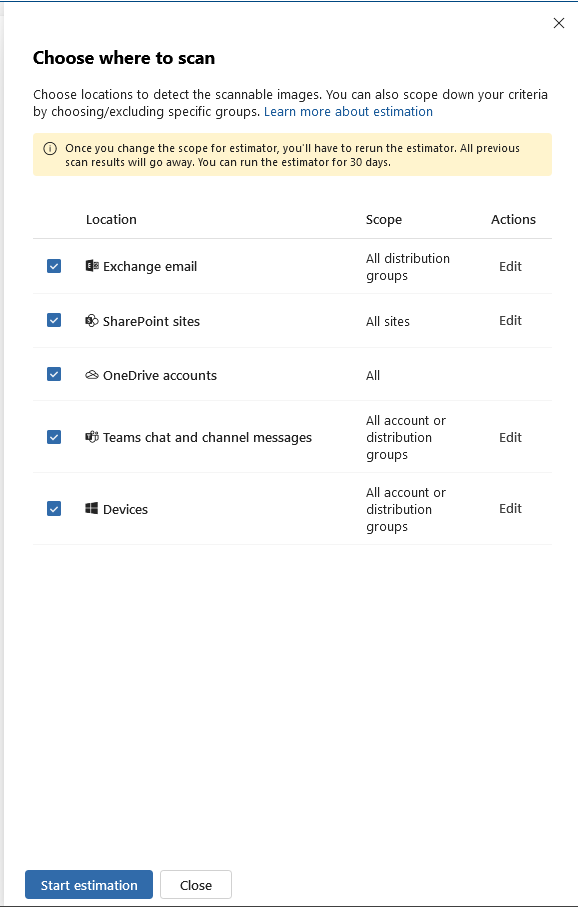
This same client later asked whether implementing sensitivity labelling for PDF files would impact their users as they have many of whom use this device for reading and annotating documents whilst travelling (especially VIPs). So…I decided to investigate.
Remarkable Paper Pro: Technical Overview
- Operating System: Codex (custom Linux-based OS)
- Supported formats: Limited to PDF and ePub
- Web capabilities: No built-in browser
File Management Options
- Email: Direct file sharing via email.
- Cable transfer: USB connection for importing/exporting
- Cloud integration: Syncs with personal Google Drive, Dropbox and OneDrive
- Remarkable custom app: The device can import files through my.remarkable.com
Device limitation (for Device Management or Data Security)
- The Operating system (a Linux OS) cannot be onboarded to Microsoft Device Management or Intune
- The Operating system does not have browser to access the Microsoft authentication portal
- Users accessing corporate data are limited to do it in 3 general ways (sending it to the device via email, via usb cable, or via syncing the files from their Personal online storage aka Personal Dropbox, OneDrive, Google Drive)
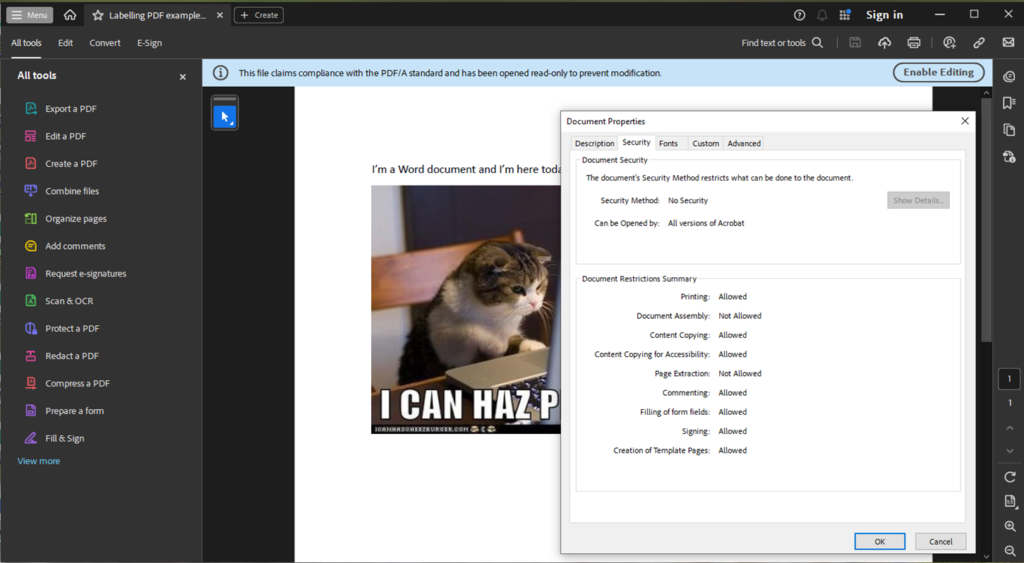
- Though reMarkable tablet can open, view, and annotate password-protected PDFs. However, this feature is limited to basic password protection and does not extend to Microsoft Purview’s advanced encryption methods, such as Rights Management Services (RMS) or Microsoft Information Protection (MIP).
Impact Assessment
Users will encounter issues only when using sensitivity labels with encryption to PDF files. This limitation exists because the Remarkable devices cannot process Microsoft Purview’s advanced encryption methods, lacking both the necessary authentication capabilities and OS support to decrypt protected content.
The device also has no browser to authenticate with Microsoft services and its custom Linux-based OS (Codex) cannot be integrated with Microsoft’s security ecosystem. This makes it not possible to work on encrypted PDFs.
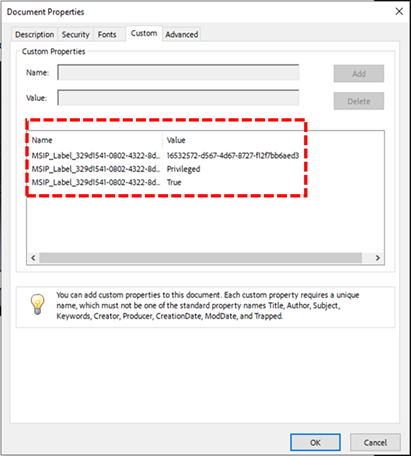
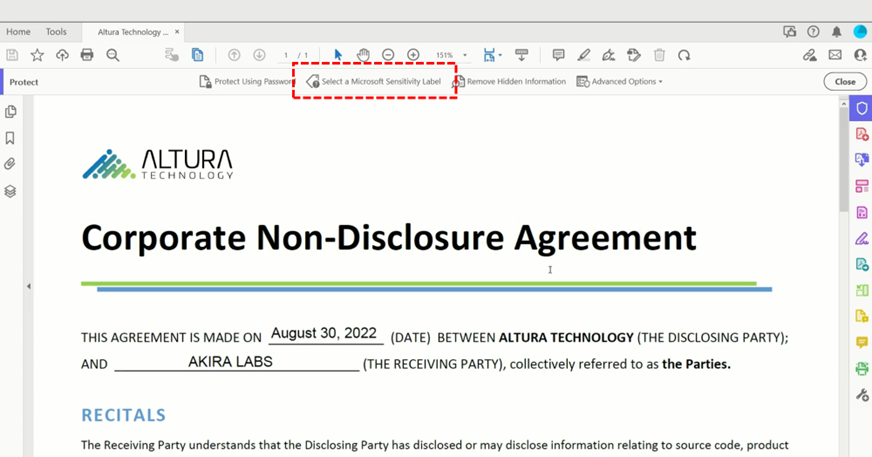
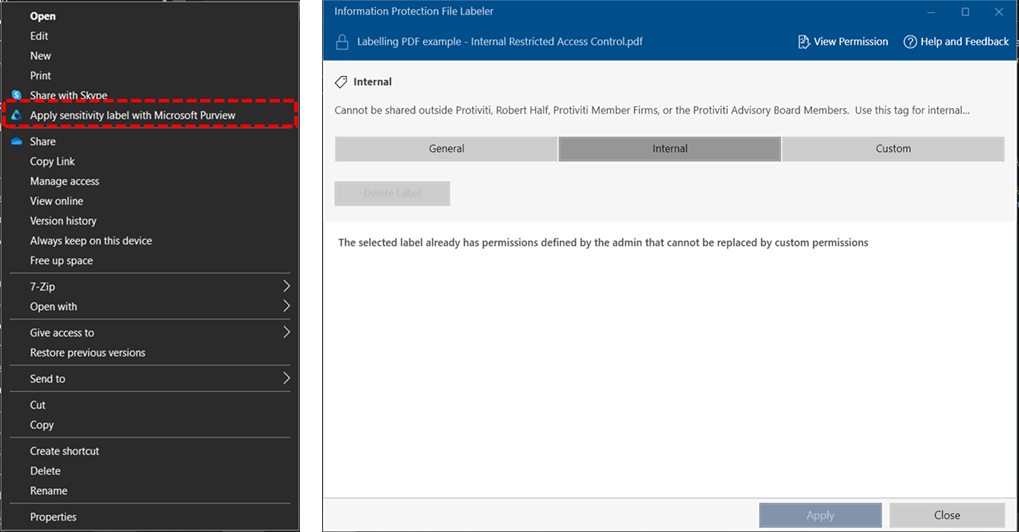
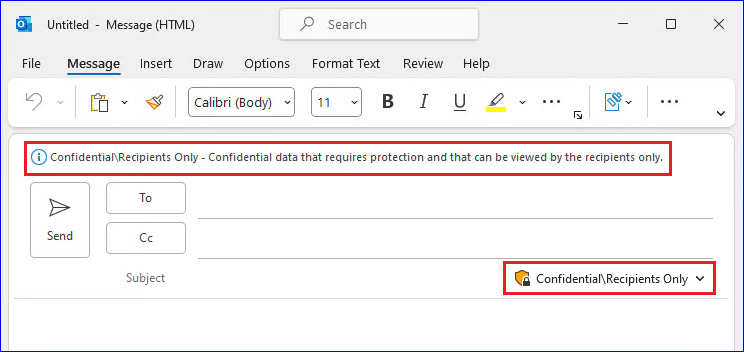
However, if PDF files are merely labelled without encryption applied (visual marking only), users will experience no impact whatsoever. These files remain fully accessible and maintain all annotation capabilities, as the labelling exists purely as metadata without affecting the file’s core accessibility.
Potential Solutions
Simple approach: Instruct executives to use sensitivity labels without encryption for PDF files they need to access on their Remarkable devices. Implement DLP monitoring to track PDFs sent to personal email addresses, providing security oversight without disrupting workflow.
Moderate approach (but Costly): Issue corporate Onyx Boox eReaders as an alternative. Onyx Boox is a direct competitor of Remarkable but the key difference is that it runs on Android OS.
The big benefit: these Android-based (Android 13 OS) devices support Microsoft authentication and can be properly integrated with MDM solutions, allowing full compatibility with encrypted documents.
It also cost less than the Remarkable Paper Pro, but buying an extra corporate device (even at $499 USD) just for reading PDF files and note taking might not be taken well by your CFO.
Complex approach: Create a special sensitivity label variant without encryption specifically for executive use cases involving eReaders. This label would maintain visual markings and tracking capabilities while ensuring accessibility on the Remarkable device.
Supporting your current Remarkable device users today.
If supporting Remarkable devices for VIP users is necessary, focus on monitoring data flow rather than blocking device use.
Set up DLP policies that track document transfers to personal emails and cloud services used with Remarkable. Include:
- Alerts when sensitive documents are transferred
- Required business justification for transfers
- Time limits on sensitive document access
- Targeted security training for Remarkable users
- Regular reviews of transferred documents
- Clear audit logs of document movement (once reviews are done)
This approach balances users device preferences with security needs. Monitoring works better than banning devices that senior staff prefer to use.
Reference:
- About Remarkable: https://support.remarkable.com/s/article/About-reMarkable-2
- Receiving email using Remarkable: Trouble sharing files via email
- Importing and Exporting files: Importing and exporting files and How to import and export files with the desktop app | reMarkable
- Integration with 3rd party file storage: 11 WAYS to UPLOAD to your reMarkable 2