
I recently applied for a U.S. visa, and as part of the process, I had to submit my passport, bank records, and a lot of personally identifiable information to the embassy in the form of PDF and JPEG files. This meant that much of my sensitive data is now stored as images. This made me wonder: How are organisations safeguarding data that is image-based rather than text-based?
Traditional Data Loss Prevention (DLP) strategies, while effective in monitoring text-based data, often fall short when it comes to image-based content. This shortcoming can lead to significant vulnerabilities, as sensitive information is frequently embedded within images (see my example above). Optical Content Recognition ( OCR) emerges as a must-have tool in addressing this gap, enabling organisations to extract and analyze text from images. For Cyber Security teams aiming to enhance their data security posture, integrating OCR into their DLP strategy is not just beneficial—it is a must!
What are the industry use cases for OCR in DLP?
- Financial services: Sensitive information such as account numbers, credit card details, and personally identifiable information (PII) is often embedded in scanned documents, receipts, and screenshots
- Healthcare industry: There are data that are in the form of Medical records and scans, prescriptions and doctor’s notes (assuming that your doctor can write legibly)
- Retail and Ecommerce: Scanned receipts and invoices and most product returns and refunds that starts in paper get scanned and stored.
- Manufacturing: Contracts, Blueprints, R&D documents and even internal presentations (most of which gets converted to either an image or a PDF)
- Government and Public Sector: Scanned copies of passports, drivers licenses and PII data, Incident reports (which again starts on paper and ends up as a image)
These are just examples of where OCR in DLP can come in to ensure that data is not leaked out.
OCR in Microsoft Purview
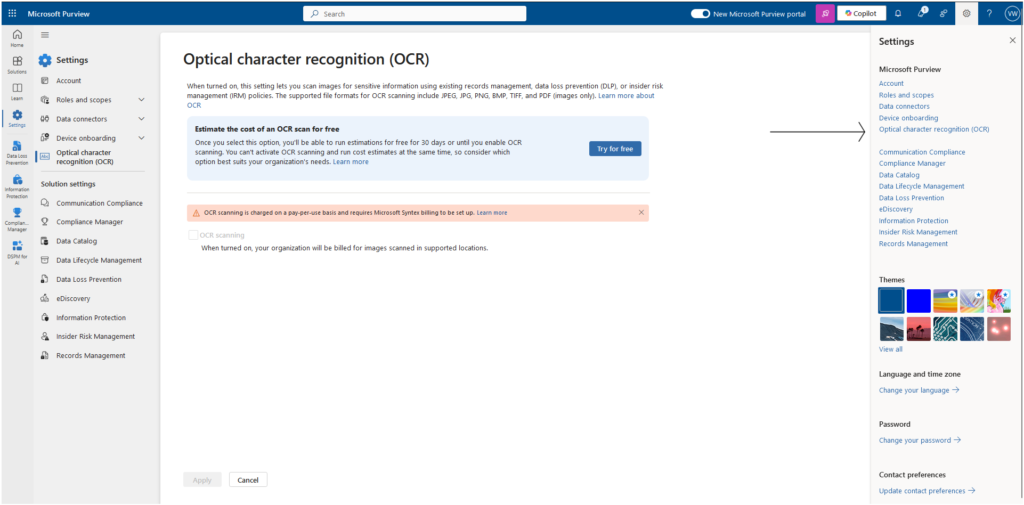
Microsoft Purview has OCR capability that allows you to be able to identify, and protect data. This allows you to scan images for Sensitive Information but do remember that this is an OPTIONAL feature and must be enabled at a Tenant level. There’s also a bit of a cost to it (more on this later)
To turn on OCR in your Microsoft Purview you’d need to do the following.
- Go to Settings > Select Optical Content Recognition.
- Choose where you want OCR to scan.
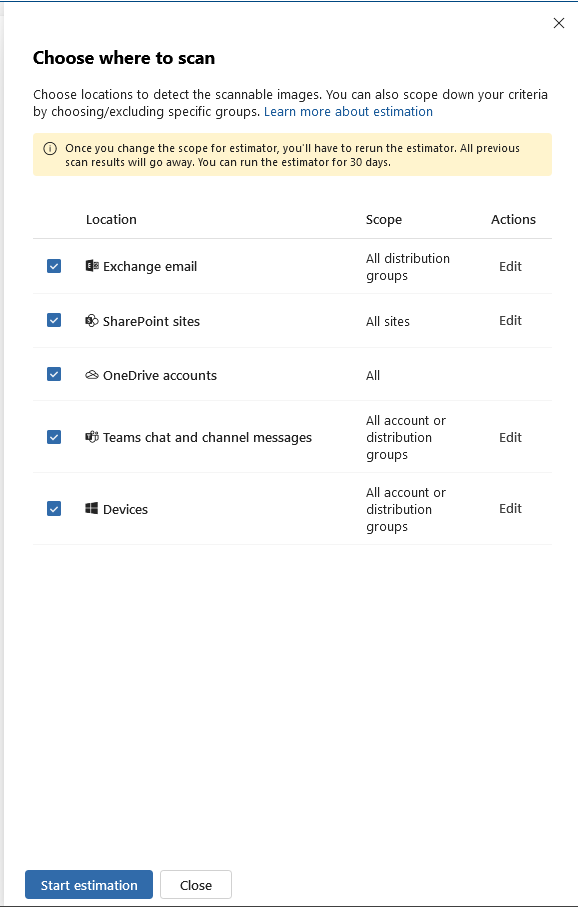
The full Technical instruction can be found here: https://learn.microsoft.com/en-us/purview/ocr-learn-about?tabs=purview#workflow-at-a-glance
The Cost of OCR
This capability is powerful as it leverages on the Azure AI to use OCR. As of today, the cost to run $1.00 USD per 1,000 scanned item. The keywords to look out for in the costing is ‘per scanned item’ this is because Microsoft considers each page in a PDF or each individual image page in a set of images as 1 scan. So a PDF that contains 10 pages counts as 10 scans. https://learn.microsoft.com/en-us/purview/ocr-learn-about?tabs=purview#estimate-your-ocr-scanning-charges
Data Strategy in using OCR for the first time.
To limit your cost and be more deliberate in running this OCR scan, here’s a helpful strategy so that you use to get started.
Data Search Using Content Search in Purview: Utilize Microsoft Purview’s Content Search feature to filter by file type, such as JPEG and PNG, to identify potential images containing sensitive information. This targeted approach ensures that all image files are scanned for embedded text.
Focus on Known Locations: Identify departments or teams that handle sensitive data, such as Finance, Sales, and Marketing, and focus OCR searches on their respective SharePoint sites. This strategy maximizes the efficiency of OCR by concentrating on areas where sensitive information is most likely to reside.
File Name Analysis: Implement keyword searches for terms that indicate sensitive content, such as “passport” or “ccn” (credit card number), in file names. This proactive approach helps in identifying and flagging files that may contain sensitive information.