In my Purview Ninja Training (you can take the training too, click here), one of the Purview capabilities that I struggled understanding at first was using the Sensitive Information Types for automatic classification. Not because it’s difficult to understand but becaue there were so many different options you can choose from that can be applied to similar use cases.
So to save time in understanding it, here is an over-simplified matrix of when to use the different automatic classification options using Microsoft Purview Information Protection.
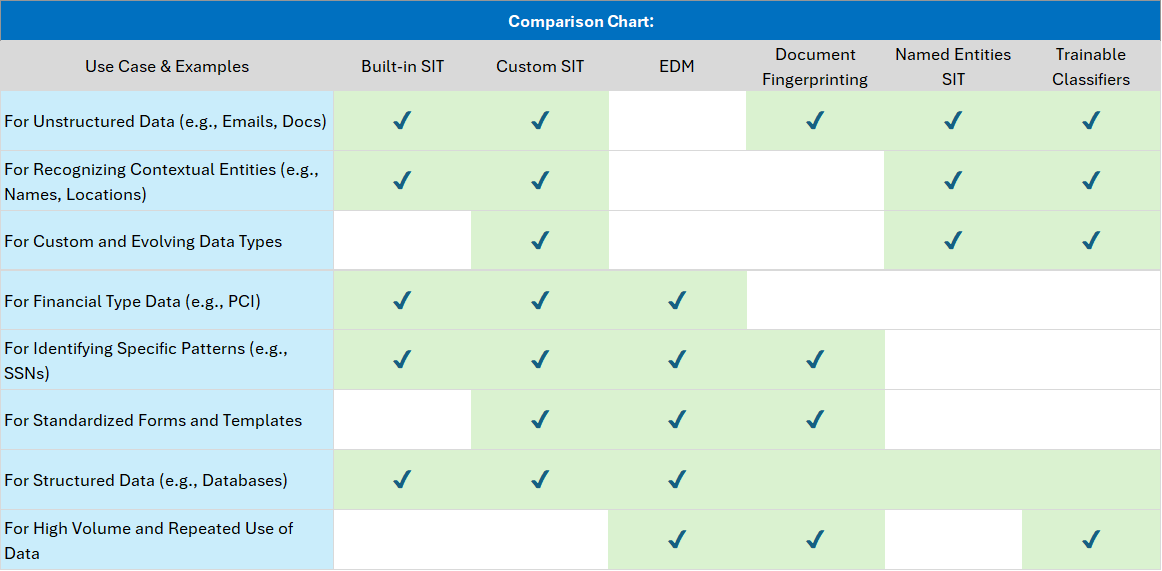
When to use each capability.
- Built-in SIT: Ready-to-use, predefined data types like social security numbers, credit card numbers, and other common sensitive data formats. Ideal for general compliance and basic data protection needs.
- Custom SIT: Customizable to meet unique organizational requirements. Suitable for both structured and unstructured data.
- EDM (Exact Data Match SITs): Best for exact matches of structured data with consistent formats, such as financial records and personal IDs.
- Document Fingerprinting: Detects and protects standardized documents with repeatable structures, like legal forms and templates.
- Named Entities SIT: Used for for detecting contextual sensitive or important data, like names or organizations, particularly within unstructured formats.
- Trainable Classifiers: Useful for complex or ever changing data types, especially in unstructured data, where static rules or patterns are inadequate